99.3% Findability with the Partial Results Feature
99.3% Findability with the Partial Results Feature

Backend Developer
My team’s goal is to imagine and develop ways that empower brands to give shoppers a positive emotional experience. As we all build our expectations and values around what we expect from the brands we buy from, the team here is evolving what is possible within Search & Discovery with the Empathy Platform.
I’m proud to say that the journey we went on to add the Partial Results feature certainly made an impact even greater than we’d expected. Here I’ll share how we got there and how we’ll continue our mission for better, more trustworthy Search experiences.
Towards perfection
Findability is a key measure for any retailer striving to offer their customers the products that best suit their needs. In the following real-world example, around 94% of our client’s customer queries were already returning relevant results. We wanted to go a step further, though, and do something about the remaining 6%.
To do this, we scheduled a series of discovery sessions with the client and came up with a series of creative solutions to cover most zero-result cases.
Spellcheck
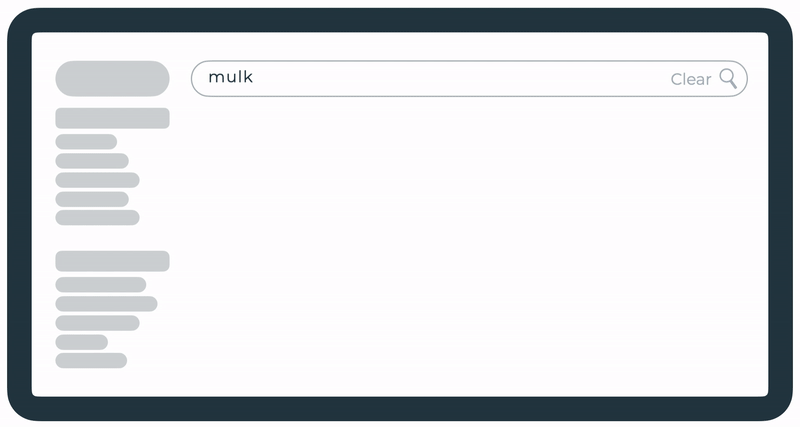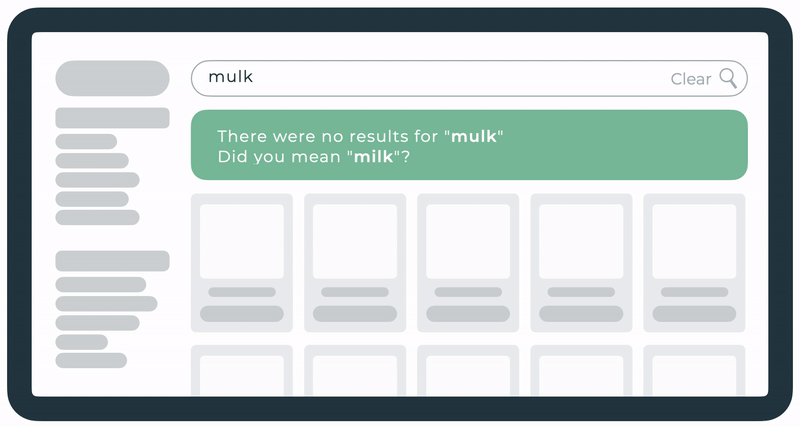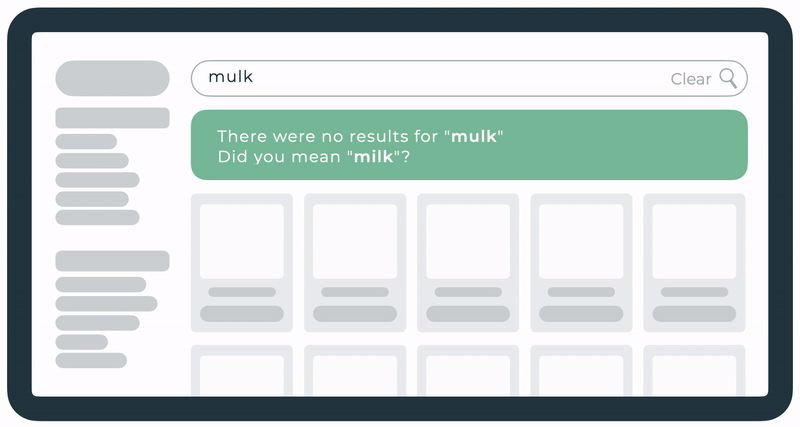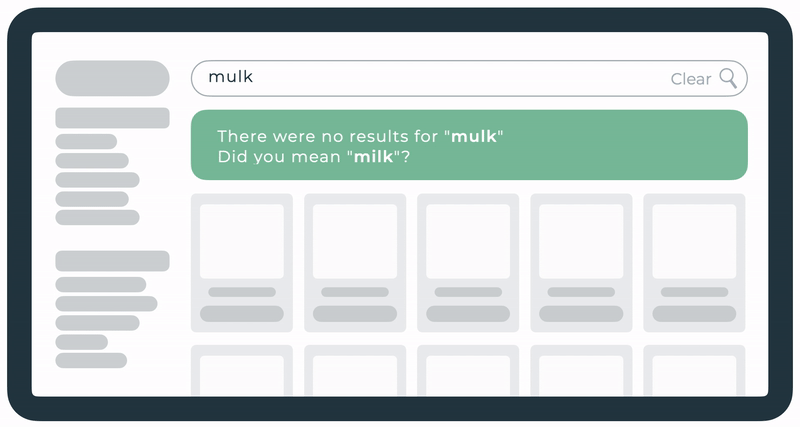
A mechanism that resolves accidentally mistyped queries. For example, “mulk” is redirected to the results of “milk”. This was already live for this client but we decided to display the details about the redirection above the search results.
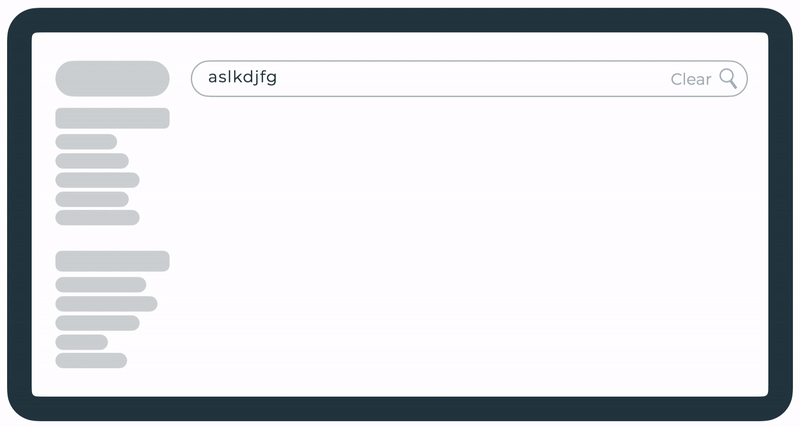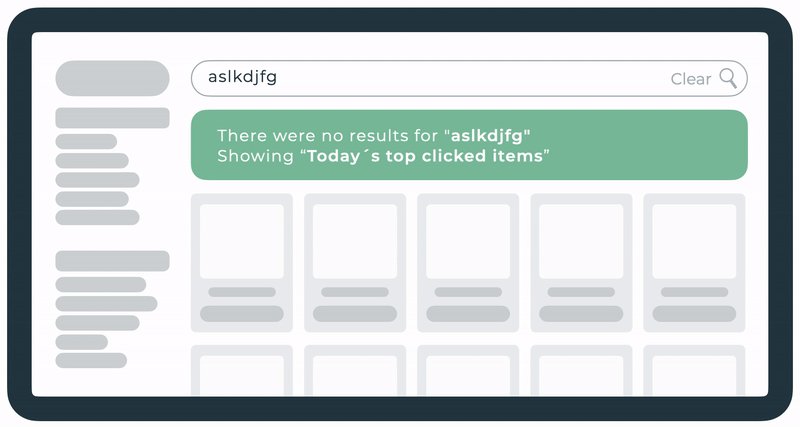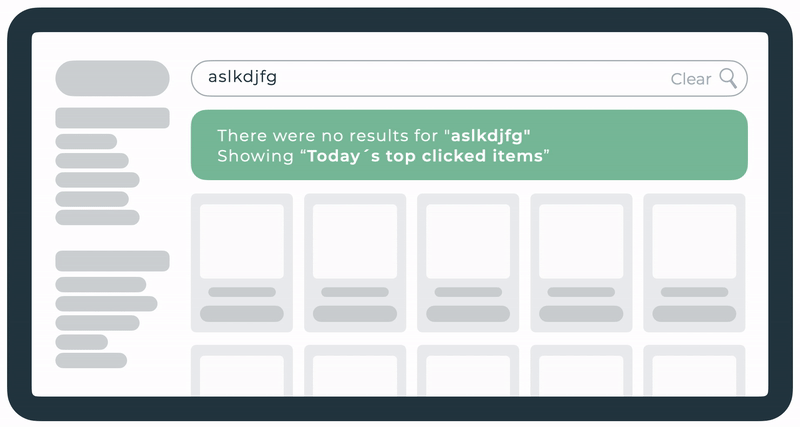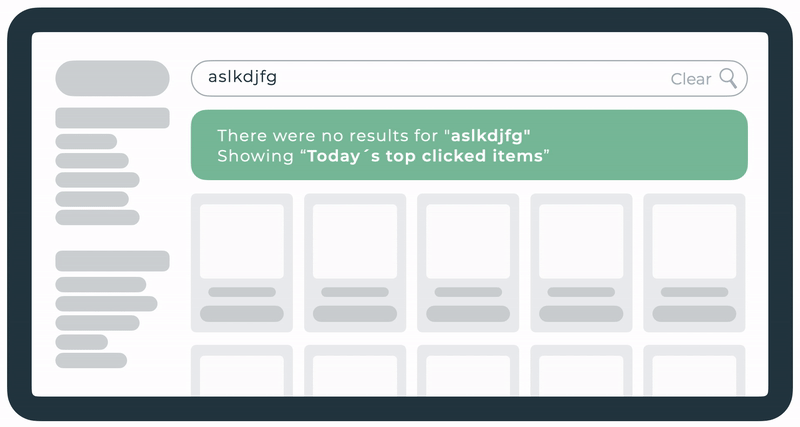
Top clicked
A landing page for shoppers showing the day’s most clicked products when no other zero results fallback is possible.
Custom message
An instant message regarding the product being searched for if, for example, it’s temporarily out of stock.
Promoted link
A mechanism to allow a redirection of the shopper to relevant information, such as, connecting “covid vaccine” with a coronavirus update page.
Promoted query
Similar to how synonyms work, we establish equivalences between terms or queries so that they match products as if they were the same term. Here, we let the shopper know about this equivalence.

Partial results
A mechanism that breaks down multi-term queries into a series of shorter queries that yield relevant results with transparency built in to explain this to the shopper.

The first thing to be implemented was the change in the spellcheck feature. After that, we decided to start working on Partial Results as it seemed to have the most potential impact on the shopper’s journey of all the zero results fallbacks.
But what exactly is the Partial Results feature?
Imagine you’re a customer looking for some tasty capsules of roast coffee from Nicaragua, but your favourite shop is out of them. The shop has other options for capsules of roast coffee and even bags of roast coffee from Nicaragua but, rather than a blank page resulting from your query, it would be much more useful to get a list of alternatives to find the finest coffee available for you. That’s when Partial Results comes in handy.
How exactly does it all work? The Partial Results functionality is conformed by a series of steps I’ll explain here. Taking our coffee query as example, the execution would go as follows:
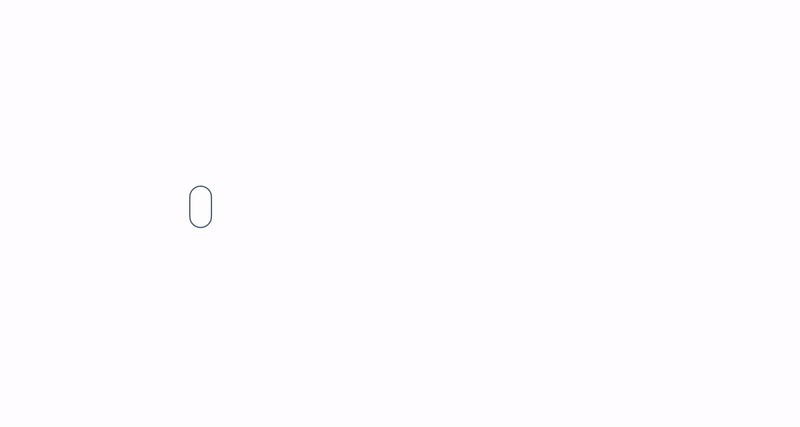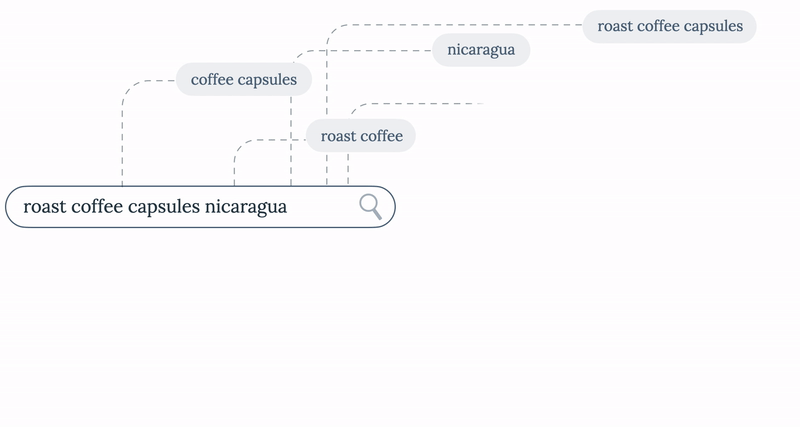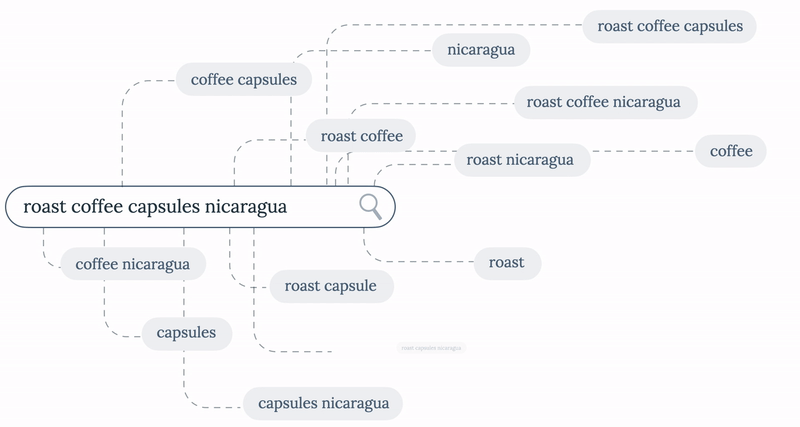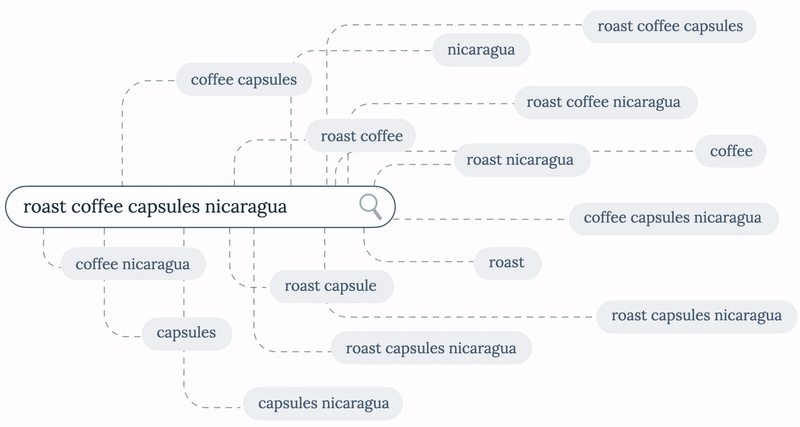
Step 1 - Break down of the original query
The query “roast coffee capsules nicaragua” has 14 possible subqueries. To avoid possible performance issues for queries over 4 terms long (a 6 term query returns 64 possible subqueries), we implemented a configurable limit, setting the maximum number of subqueries the service should try to extract.
Step 2 - Checking the potential subqueries
Once we obtain our set of potential partial results, it’s time to verify whether they would lead the shopper to any relevant results, avoiding another zero results dead end. To do this, the service builds an elasticsearch query containing all the relevant filters present in the original query and an aggregation for each of the potential partial results we got previously.
Step 3 - Picking the most relevant subqueries
Now we know which subqueries would provide the customer with results and how many results they provide, it’s time to select the most relevant ones. To do that whilst keeping our service flexible enough to modify this behaviour easily, we implemented several picking algorithms:
- Matching terms: Prioritise subqueries containing the greatest number of terms from the original query.
- Subquery length: Prioritise subqueries with the most characters.
- Hits: Prioritise subqueries yielding the greatest number of results.
- Combined: A combination of all of the above, prioritising first by Matching terms, then Subquery length, then Hits.
Going back to our 4 terms long example, the service would be able to take all the queries into account, so all of them would be carried out to the second step, and then, after querying to the elasticsearch we would get this:
Our configured algorithm of choice was Combined, so the first queries to be selected would be “roast coffee nicaragua” and “roast coffee capsules” by number of terms, then between all the 2 term long queries, “coffee nicaragua”, “roast capsules” and “coffee capsules” would be selected by character length. If we had configured a limit of just 3 partials to be returned, “coffee nicaragua” would be the third one to be picked by the algorithm, as even though it has the same number of characters as “roast nicaragua”, it yields more results.
And how did this affect the shopper’s journey in the end?
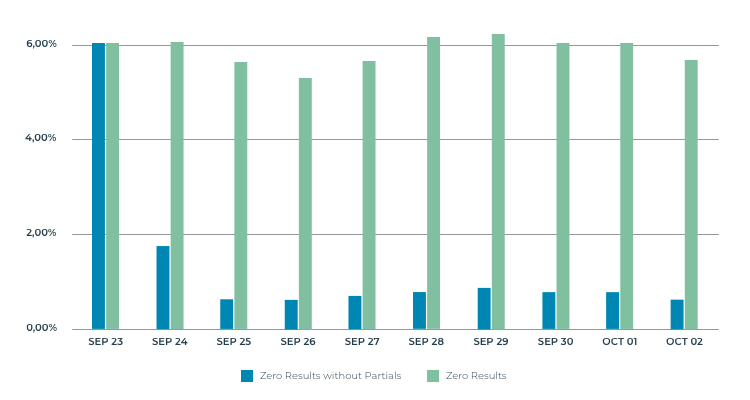
We were pretty excited about deploying this new feature to production and getting to see real customers interact with it. It’s had a great impact on that, reducing the initial number of zero results queries from almost 6% to roughly 0.7%. On top of that, 55% of partial term’s queries end up with the shopper interacting with the proposed alternatives.
But aside from those numbers, it’s also impacted greatly on the way shoppers interact with our search service. Their experience in the instances where no results were found used to be frustrating, having to rethink and rephrase their queries which took time and effort on their part. Now, we take that hassle away from them offering appropriate alternatives to choose from.
On the graph below, you can see the percentage of queries still giving out zero results for which the service wasn’t able to provide the customer with partial result alternatives (blue) vs the total percentage of zero results queries (green).
Never stop innovating
This functionality is performing exceptionally in production environments, however, we still want to continue building on its success. Giving it even more flexibility by applying improvements we make the most of the knowledge we learnt along our journey of developing this feature. Our next improvements include:
Apply stop words to the original query
At the moment, every word within the original query is read as a query term. We want to apply stop words to get rid of words like “to, from, and, a …”, reducing the number of possible combinations so the service can focus only on relevant information.
Update the way the subquery generation limit works
One of the final steps to this development consisted of executing several performance tests over it. It was time to test different configurations and see how we could get the best balance between results and performance. We found out that the generation of subqueries (step 1) was pretty cheap in terms of time so we started designing around that.
Instead of limiting the number of partials generated, we want to have an internal limit for that, applying only the former generation limit to the number of subqueries sent to the elastic. To do this, we’d use an algorithm to pick which ones we want to send. We could also make this algorithm configurable, increasing personalisation options and covering as many scenarios as possible.
Onwards & upwards
This has been an exciting journey for everyone involved, including myself, as, with this being my first end-to-end project within this service, I’ve learnt that working with the client directly and focussing on the feature that most impacted the shopper was a joy for us and a pleasure for all who will use it.
Can’t wait to tell you all about the next adventure.